AdaRL: What, Where, and How to Adapt in Transfer Reinforcement Learning
Abstract
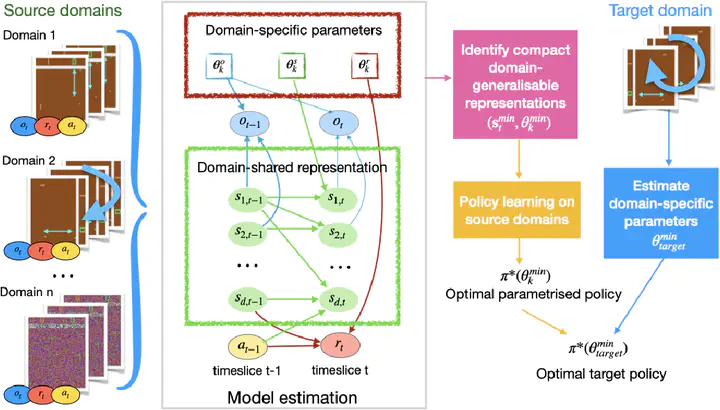
One practical challenge in reinforcement learning (RL) is how to make quick adaptations when faced with new environments. In this paper, we propose a principled framework for adaptive RL, called textitAdaRL, that adapts reliably and efficiently to changes across domains with a few samples from the target domain, even in partially observable environments. Specifically, we leverage a parsimonious graphical representation that characterizes structural relationships over variables in the RL system. Such graphical representations provide a compact way to encode what and where the changes across domains are, and furthermore inform us with a minimal set of changes that one has to consider for the purpose of policy adaptation. We show that by explicitly leveraging this compact representation to encode changes, we can efficiently adapt the policy to the target domain, in which only a few samples are needed and further policy optimization is avoided. We illustrate the efficacy of AdaRL through a series of experiments that vary factors in the observation, transition, and reward functions for Cartpole and Atari games.
Sara Magliacane
Professor
I’m a full professor at Saarland University and part of the Amsterdam Machine Learning Lab at the University of Amsterdam. I work on causality, causal representation learning and causality-inspired ML.